linux kernel allocator
Working in progress
How to read this post
This post contains a lot of “dump” of the kernel structure. Reading and memorizing each of them is time consuming and inefficient. So reading the main texts written will be more helpful. That way, you can follow how I went through debugging the code.
Also, I prefer learning by debugging and actually seeing the structures. That’s why I attached detailed outcomes of gef commands. If you prefer top-down learning, it would be better to read other blogs such as kernel docs or 문C블로그(korean, ARM linux).
Every text is written by me (not AI) unless explicitly mentioned.
Linux code analysis
high-level definitions
data types
kmem_cache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
/*
* Slab cache management.
*/
struct kmem_cache {
#ifndef CONFIG_SLUB_TINY
struct kmem_cache_cpu __percpu *cpu_slab;
#endif
/* Used for retrieving partial slabs, etc. */
slab_flags_t flags;
unsigned long min_partial;
unsigned int size; /* Object size including metadata */
unsigned int object_size; /* Object size without metadata */
struct reciprocal_value reciprocal_size;
unsigned int offset; /* Free pointer offset */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
unsigned int cpu_partial;
/* Number of per cpu partial slabs to keep around */
unsigned int cpu_partial_slabs;
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *object); /* Object constructor */
unsigned int inuse; /* Offset to metadata */
unsigned int align; /* Alignment */
unsigned int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
#ifdef CONFIG_SYSFS
struct kobject kobj; /* For sysfs */
#endif
#ifdef CONFIG_SLAB_FREELIST_HARDENED
unsigned long random;
#endif
#ifdef CONFIG_NUMA
/*
* Defragmentation by allocating from a remote node.
*/
unsigned int remote_node_defrag_ratio;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
unsigned int *random_seq;
#endif
#ifdef CONFIG_KASAN_GENERIC
struct kasan_cache kasan_info;
#endif
#ifdef CONFIG_HARDENED_USERCOPY
unsigned int useroffset; /* Usercopy region offset */
unsigned int usersize; /* Usercopy region size */
#endif
struct kmem_cache_node *node[MAX_NUMNODES];
};
kmalloc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
/**
* kmalloc - allocate kernel memory
* @size: how many bytes of memory are required.
* @flags: describe the allocation context
*
* kmalloc is the normal method of allocating memory
* for objects smaller than page size in the kernel.
*
* The allocated object address is aligned to at least ARCH_KMALLOC_MINALIGN
* bytes. For @size of power of two bytes, the alignment is also guaranteed
* to be at least to the size. For other sizes, the alignment is guaranteed to
* be at least the largest power-of-two divisor of @size.
*
* The @flags argument may be one of the GFP flags defined at
* include/linux/gfp_types.h and described at
* :ref:`Documentation/core-api/mm-api.rst <mm-api-gfp-flags>`
*
* The recommended usage of the @flags is described at
* :ref:`Documentation/core-api/memory-allocation.rst <memory_allocation>`
*
* Below is a brief outline of the most useful GFP flags
*
* %GFP_KERNEL
* Allocate normal kernel ram. May sleep.
*
* %GFP_NOWAIT
* Allocation will not sleep.
*
* %GFP_ATOMIC
* Allocation will not sleep. May use emergency pools.
*
* Also it is possible to set different flags by OR'ing
* in one or more of the following additional @flags:
*
* %__GFP_ZERO
* Zero the allocated memory before returning. Also see kzalloc().
*
* %__GFP_HIGH
* This allocation has high priority and may use emergency pools.
*
* %__GFP_NOFAIL
* Indicate that this allocation is in no way allowed to fail
* (think twice before using).
*
* %__GFP_NORETRY
* If memory is not immediately available,
* then give up at once.
*
* %__GFP_NOWARN
* If allocation fails, don't issue any warnings.
*
* %__GFP_RETRY_MAYFAIL
* Try really hard to succeed the allocation but fail
* eventually.
*/
static __always_inline __alloc_size(1) void *kmalloc_noprof(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size) && size) {
unsigned int index;
if (size > KMALLOC_MAX_CACHE_SIZE)
return __kmalloc_large_noprof(size, flags);
index = kmalloc_index(size);
return __kmalloc_cache_noprof(
kmalloc_caches[kmalloc_type(flags, _RET_IP_)][index],
flags, size);
}
return __kmalloc_noprof(size, flags);
}
#define kmalloc(...) alloc_hooks(kmalloc_noprof(__VA_ARGS__))
__kmalloc_cache_noprof is the real implementation of the kmalloc.
Following the definition, we find:
__kmalloc_cache_noprof
1
2
3
4
5
6
7
8
9
10
11
void *__kmalloc_cache_noprof(struct kmem_cache *s, gfp_t gfpflags, size_t size)
{
void *ret = slab_alloc_node(s, NULL, gfpflags, NUMA_NO_NODE,
_RET_IP_, size);
trace_kmalloc(_RET_IP_, ret, size, s->size, gfpflags, NUMA_NO_NODE);
ret = kasan_kmalloc(s, ret, size, gfpflags);
return ret;
}
EXPORT_SYMBOL(__kmalloc_cache_noprof);
KASAN is out of scope for now, so slab_alloc_node is our interest.
slab_alloc_node
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
/*
* Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc)
* have the fastpath folded into their functions. So no function call
* overhead for requests that can be satisfied on the fastpath.
*
* The fastpath works by first checking if the lockless freelist can be used.
* If not then __slab_alloc is called for slow processing.
*
* Otherwise we can simply pick the next object from the lockless free list.
*/
static __fastpath_inline void *slab_alloc_node(struct kmem_cache *s, struct list_lru *lru,
gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{
void *object;
bool init = false;
s = slab_pre_alloc_hook(s, gfpflags);
if (unlikely(!s))
return NULL;
object = kfence_alloc(s, orig_size, gfpflags);
if (unlikely(object))
goto out;
object = __slab_alloc_node(s, gfpflags, node, addr, orig_size);
maybe_wipe_obj_freeptr(s, object);
init = slab_want_init_on_alloc(gfpflags, s);
out:
/*
* When init equals 'true', like for kzalloc() family, only
* @orig_size bytes might be zeroed instead of s->object_size
* In case this fails due to memcg_slab_post_alloc_hook(),
* object is set to NULL
*/
slab_post_alloc_hook(s, lru, gfpflags, 1, &object, init, orig_size);
return object;
}
__slab_alloc_node is basically fast path. slab_pre_alloc_hook only performs check on allocation failure depending on the flags.
__slab_alloc_node
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
static __always_inline void *__slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{
struct kmem_cache_cpu *c;
struct slab *slab;
unsigned long tid;
void *object;
redo:
/*
* Must read kmem_cache cpu data via this cpu ptr. Preemption is
* enabled. We may switch back and forth between cpus while
* reading from one cpu area. That does not matter as long
* as we end up on the original cpu again when doing the cmpxchg.
*
* We must guarantee that tid and kmem_cache_cpu are retrieved on the
* same cpu. We read first the kmem_cache_cpu pointer and use it to read
* the tid. If we are preempted and switched to another cpu between the
* two reads, it's OK as the two are still associated with the same cpu
* and cmpxchg later will validate the cpu.
*/
c = raw_cpu_ptr(s->cpu_slab);
tid = READ_ONCE(c->tid);
/*
* Irqless object alloc/free algorithm used here depends on sequence
* of fetching cpu_slab's data. tid should be fetched before anything
* on c to guarantee that object and slab associated with previous tid
* won't be used with current tid. If we fetch tid first, object and
* slab could be one associated with next tid and our alloc/free
* request will be failed. In this case, we will retry. So, no problem.
*/
barrier();
/*
* The transaction ids are globally unique per cpu and per operation on
* a per cpu queue. Thus they can be guarantee that the cmpxchg_double
* occurs on the right processor and that there was no operation on the
* linked list in between.
*/
object = c->freelist;
slab = c->slab;
if (!USE_LOCKLESS_FAST_PATH() ||
unlikely(!object || !slab || !node_match(slab, node))) {
object = __slab_alloc(s, gfpflags, node, addr, c, orig_size);
} else {
void *next_object = get_freepointer_safe(s, object);
/*
* The cmpxchg will only match if there was no additional
* operation and if we are on the right processor.
*
* The cmpxchg does the following atomically (without lock
* semantics!)
* 1. Relocate first pointer to the current per cpu area.
* 2. Verify that tid and freelist have not been changed
* 3. If they were not changed replace tid and freelist
*
* Since this is without lock semantics the protection is only
* against code executing on this cpu *not* from access by
* other cpus.
*/
if (unlikely(!__update_cpu_freelist_fast(s, object, next_object, tid))) {
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH);
}
return object;
}
CONFIG_SLUB_TINYandCONFIG_NUMAare ignored.They we’ll be not displayed in the source from now on.
Tip: See [ to follow.
1
2
c = raw_cpu_ptr(s->cpu_slab);
tid = READ_ONCE(c->tid);
Fetches the per-cpu slab and tid. tid stands for transaction id. This operation is done is CPU without a lock, so the per-cpu data may change. So some validation needs to be done to check if cpu_slab’s fields are coherent. tid value is used to validate that.
The barrior is due to compiler optimization. The expected flow is:
If the compiler optimizes the flow like:
It may use updated tid.
If the conditions are not met or there is no more freelist, it goes to slow path:
__slab_alloc(s, gfpflags, node, addr, c, orig_size);If it was able to allocate from the cached freelist, it returns the object and sets prefetch hint to the CPU. (See
prefetchwinstruction if you’re interested.)
Fast path wasn’t difficult than expected.
Let’s go deeper to __slab_alloc
__slab_alloc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c, unsigned int orig_size)
{
void *p;
#ifdef CONFIG_PREEMPT_COUNT
/*
* We may have been preempted and rescheduled on a different
* cpu before disabling preemption. Need to reload cpu area
* pointer.
*/
c = slub_get_cpu_ptr(s->cpu_slab);
#endif
p = ___slab_alloc(s, gfpflags, node, addr, c, orig_size);
#ifdef CONFIG_PREEMPT_COUNT
slub_put_cpu_ptr(s->cpu_slab);
#endif
return p;
}
If preemption happens,
cmight no longer be the correct cpu. Soslub_get_cpu_ptrfixes that.
Hmm, seems like this is a wrapper too. Moving on.
(Be warned! __slab_alloc is bit long)
__slab_alloc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
/*
* Slow path. The lockless freelist is empty or we need to perform
* debugging duties.
*
* Processing is still very fast if new objects have been freed to the
* regular freelist. In that case we simply take over the regular freelist
* as the lockless freelist and zap the regular freelist.
*
* If that is not working then we fall back to the partial lists. We take the
* first element of the freelist as the object to allocate now and move the
* rest of the freelist to the lockless freelist.
*
* And if we were unable to get a new slab from the partial slab lists then
* we need to allocate a new slab. This is the slowest path since it involves
* a call to the page allocator and the setup of a new slab.
*
* Version of __slab_alloc to use when we know that preemption is
* already disabled (which is the case for bulk allocation).
*/
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c, unsigned int orig_size)
{
void *freelist;
struct slab *slab;
unsigned long flags;
struct partial_context pc;
bool try_thisnode = true;
stat(s, ALLOC_SLOWPATH);
reread_slab:
slab = READ_ONCE(c->slab);
if (!slab) {
/*
* if the node is not online or has no normal memory, just
* ignore the node constraint
*/
if (unlikely(node != NUMA_NO_NODE &&
!node_isset(node, slab_nodes)))
node = NUMA_NO_NODE;
goto new_slab;
}
if (unlikely(!node_match(slab, node))) {
/*
* same as above but node_match() being false already
* implies node != NUMA_NO_NODE
*/
if (!node_isset(node, slab_nodes)) {
node = NUMA_NO_NODE;
} else {
stat(s, ALLOC_NODE_MISMATCH);
goto deactivate_slab;
}
}
/*
* By rights, we should be searching for a slab page that was
* PFMEMALLOC but right now, we are losing the pfmemalloc
* information when the page leaves the per-cpu allocator
*/
if (unlikely(!pfmemalloc_match(slab, gfpflags)))
goto deactivate_slab;
/* must check again c->slab in case we got preempted and it changed */
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (unlikely(slab != c->slab)) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_slab;
}
freelist = c->freelist;
if (freelist)
goto load_freelist;
freelist = get_freelist(s, slab);
if (!freelist) {
c->slab = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
stat(s, ALLOC_REFILL);
load_freelist:
lockdep_assert_held(this_cpu_ptr(&s->cpu_slab->lock));
/*
* freelist is pointing to the list of objects to be used.
* slab is pointing to the slab from which the objects are obtained.
* That slab must be frozen for per cpu allocations to work.
*/
VM_BUG_ON(!c->slab->frozen);
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
return freelist;
deactivate_slab:
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (slab != c->slab) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_slab;
}
freelist = c->freelist;
c->slab = NULL;
c->freelist = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
deactivate_slab(s, slab, freelist);
new_slab:
#ifdef CONFIG_SLUB_CPU_PARTIAL
while (slub_percpu_partial(c)) {
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (unlikely(c->slab)) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_slab;
}
if (unlikely(!slub_percpu_partial(c))) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
/* we were preempted and partial list got empty */
goto new_objects;
}
slab = slub_percpu_partial(c);
slub_set_percpu_partial(c, slab);
if (likely(node_match(slab, node) &&
pfmemalloc_match(slab, gfpflags))) {
c->slab = slab;
freelist = get_freelist(s, slab);
VM_BUG_ON(!freelist);
stat(s, CPU_PARTIAL_ALLOC);
goto load_freelist;
}
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
slab->next = NULL;
__put_partials(s, slab);
}
#endif
new_objects:
pc.flags = gfpflags;
/*
* When a preferred node is indicated but no __GFP_THISNODE
*
* 1) try to get a partial slab from target node only by having
* __GFP_THISNODE in pc.flags for get_partial()
* 2) if 1) failed, try to allocate a new slab from target node with
* GPF_NOWAIT | __GFP_THISNODE opportunistically
* 3) if 2) failed, retry with original gfpflags which will allow
* get_partial() try partial lists of other nodes before potentially
* allocating new page from other nodes
*/
if (unlikely(node != NUMA_NO_NODE && !(gfpflags & __GFP_THISNODE)
&& try_thisnode))
pc.flags = GFP_NOWAIT | __GFP_THISNODE;
pc.orig_size = orig_size;
slab = get_partial(s, node, &pc);
if (slab) {
if (kmem_cache_debug(s)) {
freelist = pc.object;
/*
* For debug caches here we had to go through
* alloc_single_from_partial() so just store the
* tracking info and return the object.
*/
if (s->flags & SLAB_STORE_USER)
set_track(s, freelist, TRACK_ALLOC, addr);
return freelist;
}
freelist = freeze_slab(s, slab);
goto retry_load_slab;
}
slub_put_cpu_ptr(s->cpu_slab);
slab = new_slab(s, pc.flags, node);
c = slub_get_cpu_ptr(s->cpu_slab);
if (unlikely(!slab)) {
if (node != NUMA_NO_NODE && !(gfpflags & __GFP_THISNODE)
&& try_thisnode) {
try_thisnode = false;
goto new_objects;
}
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
stat(s, ALLOC_SLAB);
if (kmem_cache_debug(s)) {
freelist = alloc_single_from_new_slab(s, slab, orig_size);
if (unlikely(!freelist))
goto new_objects;
if (s->flags & SLAB_STORE_USER)
set_track(s, freelist, TRACK_ALLOC, addr);
return freelist;
}
/*
* No other reference to the slab yet so we can
* muck around with it freely without cmpxchg
*/
freelist = slab->freelist;
slab->freelist = NULL;
slab->inuse = slab->objects;
slab->frozen = 1;
inc_slabs_node(s, slab_nid(slab), slab->objects);
if (unlikely(!pfmemalloc_match(slab, gfpflags))) {
/*
* For !pfmemalloc_match() case we don't load freelist so that
* we don't make further mismatched allocations easier.
*/
deactivate_slab(s, slab, get_freepointer(s, freelist));
return freelist;
}
retry_load_slab:
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (unlikely(c->slab)) {
void *flush_freelist = c->freelist;
struct slab *flush_slab = c->slab;
c->slab = NULL;
c->freelist = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
deactivate_slab(s, flush_slab, flush_freelist);
stat(s, CPUSLAB_FLUSH);
goto retry_load_slab;
}
c->slab = slab;
goto load_freelist;
}
That is long.
Fortunately, there are lots of symbols and labels to help us.
-
reread_slab: Checks if the active slab is usable by checking shared memory. i.e. check for remote free.
-
load_freelist: Pin the object that will be returned
-
deactivate_slab: Let go of active slab.
-
new_slab: Reuse the CPU local partial slab. Only when
CONFIG_SLUB_CPU_PARTIALis enabled. -
new_objects: Either search for slab in the partial list or create a new one.
-
retry_load_slab: Set the obtained slab to active.
Logic follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
reread_slab
├─ current slab usable + freelist -> load_freelist -> return
├─ current slab usable + freelist refill -> load_freelist -> return
├─ current slab unusable -> deactivate_slab -> new_slab
└─ current slab empty -> new_slab
new_slab
├─ obtained from cpu partial -> load_freelist -> return
└─ failed -> new_objects
new_objects
├─ obtained from shared partial -> freeze_slab -> retry_load_slab
├─ new slab created -> retry_load_slab
└─ failed -> retry / OOM
retry_load_slab
├─ c->slab empty -> load_freelist -> return
└─ c->slab not empty -> flush and retry_load_slab
Essentially, reread_slab checks for updated slab status in the shared memory, new_slab tries to fetch one using the partial list, new_objects uses shared partial or creates a new slab, and retry_load_slab tries to load slab again.
To understand how slab is created, new_objects is our next target of analysis.
1
2
3
4
5
6
7
8
9
new_objects:
...
slab = get_partial(s, node, &pc);
... // partial routine here
// failed to find a slab
slub_put_cpu_ptr(s->cpu_slab);
slab = new_slab(s, pc.flags, node); // HERE! new slab created
c = slub_get_cpu_ptr(s->cpu_slab);
...
new_slab
1
2
3
4
5
6
7
8
9
10
static struct slab *new_slab(struct kmem_cache *s, gfp_t flags, int node)
{
if (unlikely(flags & GFP_SLAB_BUG_MASK))
flags = kmalloc_fix_flags(flags);
WARN_ON_ONCE(s->ctor && (flags & __GFP_ZERO));
return allocate_slab(s,
flags & (GFP_RECLAIM_MASK | GFP_CONSTRAINT_MASK), node);
}
allocate_slab
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
static struct slab *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct slab *slab;
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;
void *start, *p, *next;
int idx;
bool shuffle;
flags &= gfp_allowed_mask;
flags |= s->allocflags;
/*
* Let the initial higher-order allocation fail under memory pressure
* so we fall-back to the minimum order allocation.
*/
alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL;
if ((alloc_gfp & __GFP_DIRECT_RECLAIM) && oo_order(oo) > oo_order(s->min))
alloc_gfp = (alloc_gfp | __GFP_NOMEMALLOC) & ~__GFP_RECLAIM;
slab = alloc_slab_page(alloc_gfp, node, oo);
if (unlikely(!slab)) {
oo = s->min;
alloc_gfp = flags;
/*
* Allocation may have failed due to fragmentation.
* Try a lower order alloc if possible
*/
slab = alloc_slab_page(alloc_gfp, node, oo);
if (unlikely(!slab))
return NULL;
stat(s, ORDER_FALLBACK);
}
slab->objects = oo_objects(oo);
slab->inuse = 0;
slab->frozen = 0;
init_slab_obj_exts(slab);
account_slab(slab, oo_order(oo), s, flags);
slab->slab_cache = s;
kasan_poison_slab(slab);
start = slab_address(slab);
setup_slab_debug(s, slab, start);
shuffle = shuffle_freelist(s, slab);
if (!shuffle) {
start = fixup_red_left(s, start);
start = setup_object(s, start);
slab->freelist = start;
for (idx = 0, p = start; idx < slab->objects - 1; idx++) {
next = p + s->size;
next = setup_object(s, next);
set_freepointer(s, p, next);
p = next;
}
set_freepointer(s, p, NULL);
}
return slab;
}
We’ve finally arrived at the creation of a slab.
__alloc_frozen_pages_noprof
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_frozen_pages_noprof(gfp_t gfp, unsigned int order,
int preferred_nid, nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_gfp; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
if (WARN_ON_ONCE_GFP(order > MAX_PAGE_ORDER, gfp))
return NULL;
gfp &= gfp_allowed_mask;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures
* movable zones are not used during allocation.
*/
gfp = current_gfp_context(gfp);
alloc_gfp = gfp;
if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac,
&alloc_gfp, &alloc_flags))
return NULL;
/*
* Forbid the first pass from falling back to types that fragment
* memory until all local zones are considered.
*/
alloc_flags |= alloc_flags_nofragment(zonelist_zone(ac.preferred_zoneref), gfp);
/* First allocation attempt */
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac);
if (likely(page))
goto out;
alloc_gfp = gfp;
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_gfp, order, &ac);
out:
if (memcg_kmem_online() && (gfp & __GFP_ACCOUNT) && page &&
unlikely(__memcg_kmem_charge_page(page, gfp, order) != 0)) {
free_frozen_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_gfp, ac.migratetype);
kmsan_alloc_page(page, order, alloc_gfp);
return page;
}
EXPORT_SYMBOL(__alloc_frozen_pages_noprof);
This is the buddy allocator.
kmem_cache_alloc
This ultimately converges to slab_alloc_node as well.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache.
* See kmem_cache_zalloc() for a shortcut of adding __GFP_ZERO to flags.
*
* Return: pointer to the new object or %NULL in case of error
*/
void *kmem_cache_alloc_noprof(struct kmem_cache *cachep,
gfp_t flags) __assume_slab_alignment __malloc;
#define kmem_cache_alloc(...) alloc_hooks(kmem_cache_alloc_noprof(__VA_ARGS__))
void *kmem_cache_alloc_lru_noprof(struct kmem_cache *s, struct list_lru *lru,
gfp_t gfpflags) __assume_slab_alignment __malloc;
#define kmem_cache_alloc_lru(...) alloc_hooks(kmem_cache_alloc_lru_noprof(__VA_ARGS__))
1
2
3
4
5
6
7
8
9
10
11
12
void *kmem_cache_alloc_lru_noprof(struct kmem_cache *s, struct list_lru *lru,
gfp_t gfpflags)
{
// HERE!!!
void *ret = slab_alloc_node(s, lru, gfpflags, NUMA_NO_NODE, _RET_IP_,
s->object_size);
trace_kmem_cache_alloc(_RET_IP_, ret, s, gfpflags, NUMA_NO_NODE);
return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc_lru_noprof);
kmem_cache_create
Dynamic Analysis
kmalloc caches
Where everything starts
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
gef> p kmalloc_caches
$1 = {
[0x0] = {
[0x0] = 0x0,
[0x1] = 0xffff888002441200,
[0x2] = 0xffff888002441300,
[0x3] = 0xffff888002441400,
[0x4] = 0xffff888002441500,
[0x5] = 0xffff888002441600,
[0x6] = 0xffff888002441700,
[0x7] = 0xffff888002441800,
[0x8] = 0xffff888002441900,
[0x9] = 0xffff888002441a00,
[0xa] = 0xffff888002441b00,
[0xb] = 0xffff888002441c00,
[0xc] = 0xffff888002441d00,
[0xd] = 0xffff888002441e00
},
[0x1] = {
...
},
[0x2] = {
...
}
}
e.g. kmalloc_cache[0][6] stores struct* kmem_cache
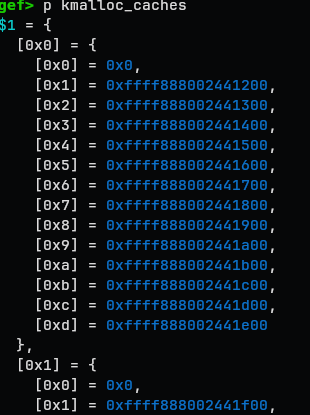

the index here represents the order class of the cache.
kmalloc_caches[type][idx]
kmem_cache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
gef> p *(struct kmem_cache *)kmalloc_caches[0][6]
$4 = {
cpu_slab = 0xffffffff820e2640,
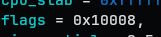
flags = 0x10008,
min_partial = 0x5,
size = 0x40,
object_size = 0x40,
reciprocal_size = {
m = 0x1,
sh1 = 0x1,
sh2 = 0x5
},
offset = 0x20,
cpu_partial = 0x78,
cpu_partial_slabs = 0x4,
oo = {
x = 0x40
},
min = {
x = 0x40
},
allocflags = 0x40000,
refcount = 0x5,
ctor = 0x0,
inuse = 0x40,
align = 0x40,
red_left_pad = 0x0,
name = 0xffffffff819d91cb "kmalloc-64",
list = {
next = 0xffff888002441668,
prev = 0xffff888002441868
},
kobj = {
name = 0xffff8880030424c0 ":0000064",
entry = {
next = 0xffff888002441680,
prev = 0xffff888002441880
},
parent = 0xffff888003020018,
kset = 0xffff888003020000,
ktype = 0xffffffff8181af00 <slab_ktype>,
sd = 0xffff888003013330,
kref = {
refcount = {
refs = {
counter = 0x1
}
}
},
state_initialized = 0x1,
state_in_sysfs = 0x1,
state_add_uevent_sent = 0x0,
state_remove_uevent_sent = 0x0,
uevent_suppress = 0x0
},
remote_node_defrag_ratio = 0x3e8,
node = {
[0x0] = 0xffff8880024401c0,
[0x1] = 0x0,
[0x2] = 0x0,
[0x3] = 0x0,
[0x4] = 0x0,
[0x5] = 0x0,
[0x6] = 0x0,
[0x7] = 0x0,
<rests are invalid values>
}
}
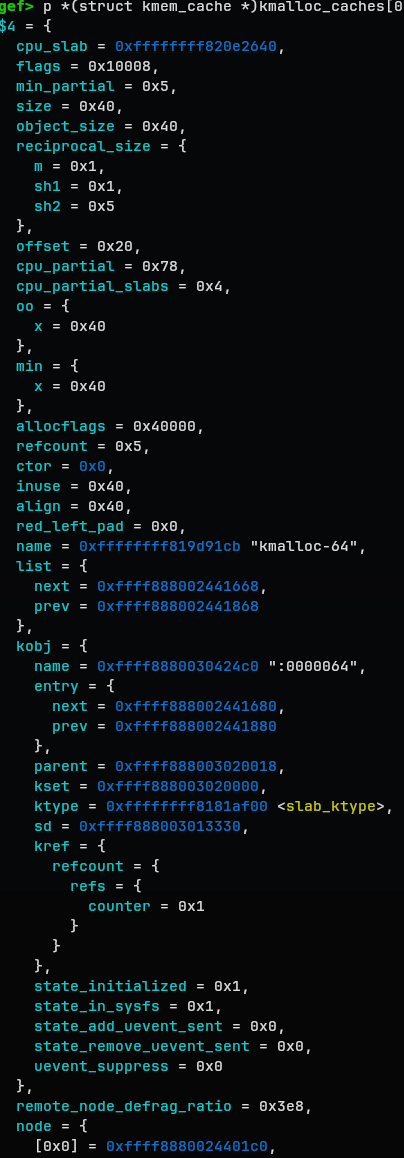
kmem_cache stores the metadata for cache.
cpu_slab

Before analyzing the cpu_slab, let’s recap the cache management
info
- CPU active slab
- slab that is utilized by some CPU as a fast path
- CPU partial
- spare partial slab which that CPU is holding
- node partial
- shared partial slab, which is not ‘owned’ by a certain CPU
- full
- slab without free object
- empty
- slab without used object
Definition:
1
struct kmem_cache_cpu __percpu *cpu_slab
The cpu_slab holds the percpu pointer to kmem_cache_cpu
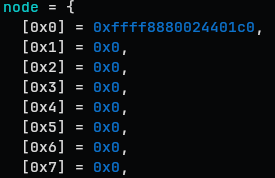
gef> p *(struct kmem_cache_cpu *)((long long)__per_cpu_offset[0]+ (long long)kmalloc_caches[0][6]->cpu_slab)
$14 = {
{
{
freelist = 0xffff88800301d5c0,
tid = 0xd300
},
freelist_tid = {
{
freelist = 0xffff88800301d5c0,
counter = 0xd300
},
full = 0xd300ffff88800301d5c0
}
},
slab = 0xffffea00000c0740,
partial = 0xffffea0000094500,
lock = {<No data fields>}
}
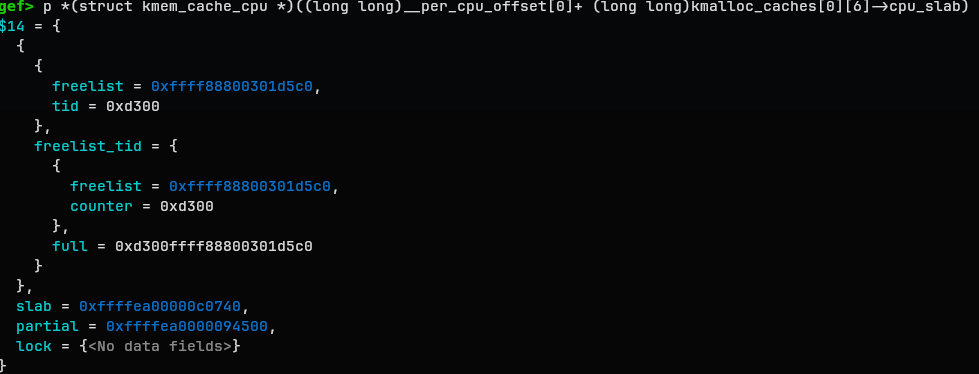
This is how it looks.
There are a freelist, addr to slab, partial list.
You might notice that address calculation is bit overwhelming. That is because the per-CPU address is represented differently. the address for cpu_slab is logically shared between the CPUs but each CPU manages its own cpu_slab, so is is rather copies of one variable that are spread throughout the CPUs.
actual_ptr_for_cpu_n = p + __per_cpu_offset[n]
The OS maintains __per_cpu_offset to keep track of those variables. So layout looks more like this:
1
2
3
4
CPU0 per-cpu region -> varA real Addr: varA + __per_cpu_offset[0]
CPU1 per-cpu region -> varA real Addr: varA + __per_cpu_offset[1]
CPU2 per-cpu region -> varA real Addr: varA + __per_cpu_offset[2]
...
The slab here is one that is used actively by the CPU.
One interesting thing you can find is that the slab pointer does not really reflect the latest freelist state. That is because frozen slab is being used by a CPU and NOT updated to shared memory
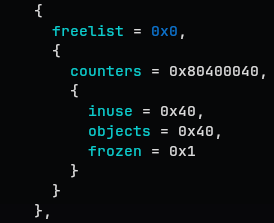
The above frozen=0x1 supports that.
We’ll deal with frozen as well later(hopefully.)
flags
Currently not our interest, but here a dump made by gpt.
| Flag | Common | Purpose | Notes |
|---|---|---|---|
SLAB_HWCACHE_ALIGN |
★ | Align objects to hardware cache-line boundaries. | For small objects, alignment may be reduced to fractions of a cache line; if an explicit alignment is also requested, the larger alignment wins. (GitHub) |
SLAB_CACHE_DMA |
Allocate backing pages from GFP_DMA memory. |
Used for old/strict DMA-addressing constraints. (GitHub) | |
SLAB_CACHE_DMA32 |
Allocate backing pages from GFP_DMA32 memory. |
Used when allocations must stay within 32-bit DMA-addressable memory. (GitHub) | |
SLAB_PANIC |
Panic if kmem_cache_create() fails. |
For caches so fundamental that failure is unrecoverable. (GitHub) | |
SLAB_TYPESAFE_BY_RCU |
★ | Delay freeing of the slab page by an RCU grace period. | Important: this does not delay freeing of the individual object; the address may be reused for another object before the grace period ends, so callers need independent object validation. (GitHub) |
SLAB_DEBUG_OBJECTS |
Enable integration with debug-objects tracking. | Relevant when debug-objects support is enabled. (GitHub) | |
SLAB_NOLEAKTRACE |
Exclude the cache from kmemleak tracing. | Useful when kmemleak tracking would be misleading or noisy for that cache. (GitHub) | |
SLAB_RECLAIM_ACCOUNT |
★ | Mark objects as reclaimable. | Part of merge comparison; reclaimable slab memory contributes to reclaimable slab accounting. (Kernel Documentation) |
SLAB_TEMPORARY |
Alias of SLAB_RECLAIM_ACCOUNT. |
Not a distinct behavior bit; same meaning as reclaim-accounted. (GitHub) | |
SLAB_ACCOUNT |
★ | Account all allocations from this cache to memcg. | Applies regardless of whether individual allocations pass __GFP_ACCOUNT. (Kernel Documentation) |
SLAB_NO_USER_FLAGS |
Ignore user-supplied slab-debug flags for this cache. | Prevents external slab_debug= style settings from altering the cache’s debug behavior. (GitHub) |
|
SLAB_KMALLOC |
Mark the cache as a kmalloc slab. | Internal identification flag for kmalloc-family caches. (GitHub) | |
SLAB_NO_MERGE |
Prevent slab-cache merging. | Used when cache identity/layout must stay distinct; merge logic also treats several other flags as unmergeable. (GitHub) | |
SLAB_CONSISTENCY_CHECKS |
Perform expensive consistency checks on alloc/free. | Debug flag; useful for allocator bug hunting. (GitHub) | |
SLAB_RED_ZONE |
Add red zones around objects. | Debug flag for detecting overflows/underruns around object boundaries. (GitHub) | |
SLAB_POISON |
Poison objects/padding with known patterns. | Debug flag for catching use-after-free and memory corruption patterns. (GitHub) | |
SLAB_STORE_USER |
Store allocation/free ownership information. | Debug flag for tracing who last touched an object. (GitHub) | |
SLAB_TRACE |
Trace allocation/free activity. | Debug flag; can generate a lot of output, so it is usually enabled selectively. (GitHub) |
min_partial, size, object_size, reciprocal_size
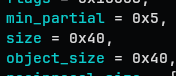
-
min_partial: how many partial slab should be prepared
-
size: actual size allocated in memory (per object) → may be bigger than object_size
-
object_size: size of the target object of allocation
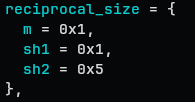
- reciprocal_size: an cache value for optimizing reciprocal divide
kernel does not like to perform N/d since division is expensive.
t = \text{high}32(n * m) \ q = (t + ((n - t) » sh1)) » sh2
q is the quotient here.
offset
offset = 0x20 is the offset of free pointer in the freelist. This make the kernel heap to be more resistant to overflow.
offset 0x00 0x20 0x40
|---------------------------|---------------------------|
[ object data(junk) ][ freepointer ]
cpu_partial, cpu_partial_slabs, oo, min
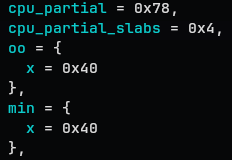
-
cpu_partial: limit for the number of free objects
-
cpu_partial_slab: limit for the number of partial slabs
e.g. freelist: A→B→C→D in slab X, freelist: A’→B’→C’→D’ in slab Y
→ 8 < cpu_partial
→ 2 < cpu_parital_slabs
-
oo: the size that will be used when creating a new slab
-
min: the minimum size that will be used when creating a new slab
In some cases where the alignment gets complicated,
min = order 0, objects 37
oo = order 1, objects 80
This kind of thing may happen
allocflags

The flag for GFP bits.
Below is the gpt generated table
Item in allocflags |
Common | Meaning | When it gets added |
|---|---|---|---|
__GFP_COMP |
★ | Treat the allocated backing pages as a compound allocation. | Added unconditionally when SLUB sets up the cache. |
GFP_DMA |
Force slab backing pages to come from DMA-capable low memory. | Added when the cache has SLAB_CACHE_DMA. |
|
GFP_DMA32 |
Force slab backing pages to come from 32-bit DMA-addressable memory. | Added when the cache has SLAB_CACHE_DMA32. |
|
__GFP_RECLAIMABLE |
★ | Mark the slab pages as reclaimable. | Added when the cache has SLAB_RECLAIM_ACCOUNT. |
refcount
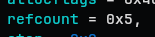
refcount hold the number of kmem_cache referenced. For example foo_cache = kmem_cache_create("foo", 64, 64, flags, NULL); will increase the refcount by 1. One interesting behavior of the kernel is that is the kmem_cache can be reused, it can get alias or merged. Such cases will increase the refcount.
When the refcount reaches 0, the kernel may free the kmem_cache structure, but only when all the conditions are satisfied.
The aliasing and merging will be dealt later.
ctor, inuse, align, red_left_pad, name
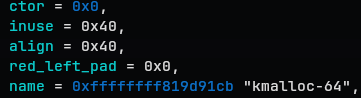
-
ctor: function pointer for constructor of the object. Get’s called when new slab is being prepared.
-
inuse: meaningful part in the allocated size
-
align: the alignment of the object
-
red_left_pad: debug or ASAN fields
-
name: the name! In this case, “kmalloc-64”
The object_size, inuse, size are confusing…
Generally speaking, object_size <= inuse <= size holds.
Here’s a visual explanation:
1
2
3
4
An object placed in the slab looks like this
|<--------- size --------->|
|<---- inuse ---->|< tail >|
|< object_size >|< extra >|
1
2
3
4
5
6
7
8
9
object_size = 48
inuse = 56
size = 64
+-------------------------------+----------+--------+
| object payload 48B | redzone | tail |
| | 8B | 8B |
+-------------------------------+----------+--------+
0 48 56 64
list
A linked list for enumerating the kmem_cache objects in special cases.
kobj
This is NOT directly related to the allocator. Rather, this is a part of linux kernel’s object management.
remote_node_defrag_ratio

This is related to NUMA model. Important but not for now.
Let’s just say
Preference of how much remote_node will be used
node
In the NUMA model, there are multiple ‘nodes’. And the allocation algorithm goes like:
1
2
3
4
5
6
7
8
9
10
11
12
Freelist is empty!
|
+-- Is there a usable slab in the CPU local partial?
| -> use that!
|
+-- Is there a usable slab in the local node partial?
| -> use that!
|
+-- Should I get remote node partial?
| -> remote_node_defrag_ratio will decide
|
`-- Create local slab
Node is a list of other nodes in this context.
This was the structure of kmem_cache.
kmem_cache_cpu
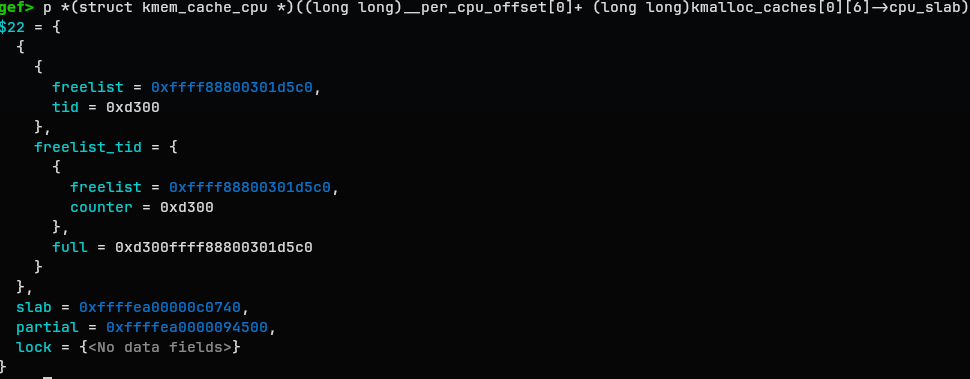
See [cpu_slab](#cpu_slab) for details
1
2
3
4
c->partial
|
v
slab A -> slab B -> slab C -> NULL
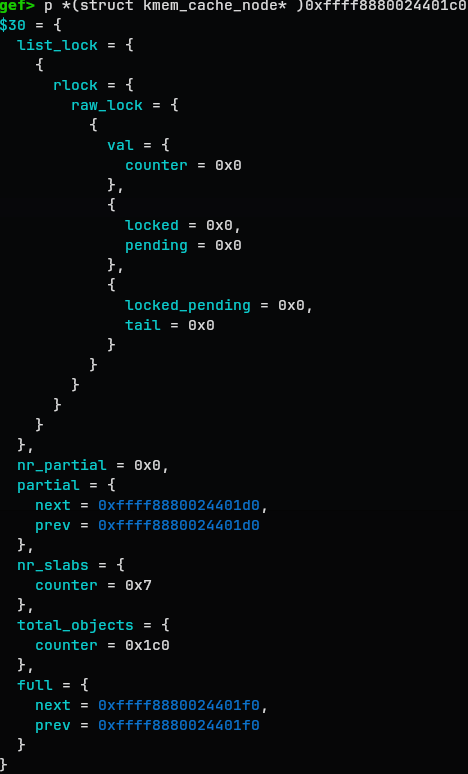
kmem_cache_node
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
gef> p *(struct kmem_cache_node* )0xffff8880024401c0
$30 = {
list_lock = {
{
rlock = {
raw_lock = {
{
val = {
counter = 0x0
},
{
locked = 0x0,
pending = 0x0
},
{
locked_pending = 0x0,
tail = 0x0
}
}
}
}
}
},
nr_partial = 0x0,
partial = {
next = 0xffff8880024401d0,
prev = 0xffff8880024401d0
},
nr_slabs = {
counter = 0x7
},
total_objects = {
counter = 0x1c0
},
full = {
next = 0xffff8880024401f0,
prev = 0xffff8880024401f0
}
}
slab
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
$23 = {
__page_flags = 0x100000000000000,
slab_cache = 0xffff888002441700,
{
{
{
slab_list = {
next = 0xdead000000000122,
prev = 0x0
},
{
next = 0xdead000000000122,
slabs = 0x0
}
},
{
{
freelist = 0x0,
{
counters = 0x80400040,
{
inuse = 0x40,
objects = 0x40,
frozen = 0x1
}
}
},
freelist_counter = {
{
freelist = 0x0,
counter = 0x80400040
},
full = 0x804000400000000000000000
}
}
},
callback_head = {
next = 0xdead000000000122,
func = 0x0
}
},
__page_type = 0xf5000000,
__page_refcount = {
counter = 0x0
}
}
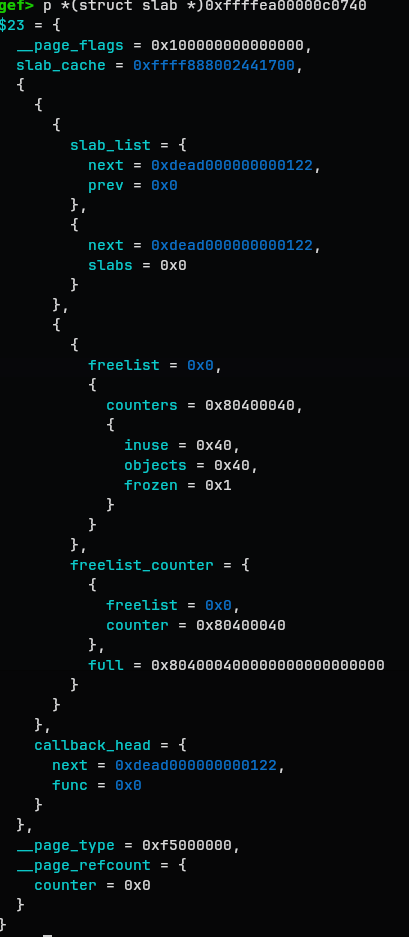
The slab structure is saved at page metadata space.