ML - 08 Gradient Descent
Introduction to Machine Learning 강의의 8번째 강의인 Gradient Descent에 대한 정리.
Basic Idea
우리는 최적의 parameter을 찾아야할 때가 종종 있다. 수식으로는 아래처럼 되겠다.
\[\theta^* = \arg\min_\theta J(\theta)\]실제 ML에서 이 문제는 $J$가 cost function이고 $\Theta$가 매개변수인 상황으로 등장한다. $J$는 $\Theta$의 함수이므로, $J(\Theta)$로 표현할 수 있다.
먼저 1차원에서는 아래 문제를 이렇게 접근할 수 있다:
- 옆으로 이동
- 값이 증가했는지 확인
- 값이 증가했다면, 반대로 이동
- 값이 감소했다면, 같은 방향으로 이동
- 1-4를 반복
이걸 pseudo code로 표현하면 아래와 같다:
\[\begin{aligned} &\textbf{Algorithm 1D-Gradient-Descent}(\Theta_{\text{init}}, \eta, f, f', \epsilon) \\[0.4em] &\begin{array}{r@{\quad}l} 1 & \Theta^{(0)} = \Theta_{\text{init}} \\ 2 & t = 0 \\ 3 & \textbf{while } |f(\Theta^{(t)}) - f(\Theta^{(t-1)})| > \epsilon \textbf{ do} \\ 4 & \qquad t = t + 1 \\ 5 & \qquad \Theta^{(t)} = \Theta^{(t-1)} - \eta f'(\Theta^{(t-1)}) \\ 6 & \textbf{return } \Theta^{(t)} \end{array} \end{aligned}\]여기서는 알고리즘의 종료 조건을 $f(\Theta^{(t)})$와 $f(\Theta^{(t-1)})$의 차이가 $\epsilon$보다 큰 경우로 설정했다. 하지만 꼭 이렇게만 잡을 필요는 없다.
$t = T$ 일 때 종료
$||\Theta^{(t)} - \Theta^{(t-1)}|| < \epsilon$ 일 때 종료
$||f’(\Theta^{(t)})|| < \epsilon$ 일 때 종료
모두 가능하다.
Theorem
만약 $J$가 Convex(아래로 볼록)이라면 어떠한 목표 정확도 $\epsilon$에 대해서 gradient descent 가 최적의 $\Theta$에 수렴하게 하는 step size $\eta$가 존재한다.
다만, $\eta$를 너무 크게 잡으면 수렴하지 않고 진동하거나 발산할 수 있다. $\eta$가 너무 작으면 수렴하는데 너무 오래 걸릴 수 있다.
Multivariate Gradient Descent
다변수에서도 동일하다. 다만, 다변수 미적분학의 배경지식을 요구하게 된다.
먼저 $J$의 $\Theta$에 대한 Gradient를 구하고, $J’$ 부분을 gradient로 바꿔주면 된다.
\[\nabla_{\Theta} J(\Theta) = \begin{bmatrix} \dfrac{\partial J(\Theta)}{\partial \theta_1} \\[0.4em] \vdots \\[0.4em] \dfrac{\partial J(\Theta)}{\partial \theta_n} \end{bmatrix}\] \[\Theta^{(t)} = \Theta^{(t-1)} - \eta \nabla_{\Theta} J(\Theta^{(t-1)})\]그리고 종료 조건도 Norm 형태나 gradient의 Norm 형태로 바꿔주면 된다.
Applications of Gradient Descent
Logistic Regression
Recap으로 Logistic Regression의 cost function은 아래와 같다:
\[J_{lr}(\Theta) = \frac{1}{n} \sum_{i=1}^{n} (\mathcal{L}_{nll}(g^{(i)}, y^{(i)})) + \frac{1}{2} \lambda ||\Theta||^2\]여기서 $\mathcal{L}_{nll}$는 Negative Log Likelihood의 약자이고 $g^{(i)} = \sigma(\Theta^T x^{(i)} + \theta_0)$이다.
한 번 여기에 gradient descent를 적용해보자. 먼저 $\mathcal{L}_{nll}$의 $\Theta$에 대한 gradient는 아래처럼 나오므로
\[\nabla_{\Theta} \mathcal{L}_{nll}(g^{(i)}, y^{(i)}) = (g^{(i)} - y^{(i)}) x^{(i)}\]따라서 $J_{lr}$의 $\Theta$에 대한 gradient는 아래처럼 나온다:
\[\nabla_{\Theta} J_{lr}(\Theta) = \frac{1}{n} \sum_{i=1}^{n} (g^{(i)} - y^{(i)}) x^{(i)} + \lambda \Theta\]매우 자세한 설명
먼저 논의를 천천히 진행하기에 앞서 정확히 문제 상황을 짚고 가자.
$x^{(i)}$는 $d$개의 feature을 가진 input vector, $y^{(i)}$는 $x^{(i)}$에 대한 binary label이다. 모델의 parameter는 bias term $\theta_0$과 weight vector $\theta$로 구성되어 있고 $\Theta = \begin{bmatrix} \theta_0 & \theta^T \end{bmatrix} ^T$로 표현할 수 있다.
\[\begin{align*} x^{(i)} & \in \mathbb{R}^{d \times 1} \\ y^{(i)} & \in \{0, 1\} \\ \theta & \in \mathbb{R}^{d \times 1} \\ \Theta & \in \mathbb{R}^{(d+1) \times 1} \end{align*}\]위와 같은 차원을 가진다.
그러면 모델의 선형적인 점수는 $z^{(i)} = \theta^T x^{(i)} + \theta_0$로 표현할 수 있다. 그리고 이 점수에 시그모이드 함수를 적용해서 $g^{(i)} = \sigma(z^{(i)})$로 표현할 수 있다. $g^{(i)} = P(y^{(i)} = 1 | x^{(i)}; \Theta)$로도 표현할 수 있다. 풀어쓰자면 Logistic Regression 모델에서 $g^{(i)}$는 $x^{(i)}$가 클래스 1에 속할 확률을 나타낸다.
한편 $y^{(i)}=0$일 확률도 포함해서 쓰면
\[P(y^{(i)} | x^{(i)}; \Theta) = (g^{(i)})^{y^{(i)}} (1 - g^{(i)})^{1 - y^{(i)}}\]로 표현할 수 있다.
이제 이 $P$를 최대화하는 $Theta$를 찾는 것이 목표이다. 앞선 Gradient Descent에서 보았듯 Convex Optimization으로 푸는 것이 쉽고 log 형태가 다루기가 좋다. 따라서 $-log$를 취해서 Negative Log Likelihood로 바꿔보자.
\[\mathcal{L}_{nll}(g^{(i)}, y^{(i)}) = -\log P(y^{(i)} | x^{(i)}; \Theta) = -\log ((g^{(i)})^{y^{(i)}} (1 - g^{(i)})^{1 - y^{(i)}})\] \[\therefore \mathcal{L}_{nll}(g^{(i)}, y^{(i)}) = -\left[ y^{(i)} \log g^{(i)} + (1 - y^{(i)}) \log (1 - g^{(i)}) \right]\]그리고 전체 training set에서 평균을 취하면,
\[\frac{1}{n} \sum_{i=1}^{n} \mathcal{L}_{nll}(g^{(i)}, y^{(i)})\]위 식이 유도된다.
한편 parameter가 지나치게 커지는 것을 방지하기 위해서 regularization term도 추가해보자. $L2$ regularization term는 $\frac{1}{2} \lambda ||\Theta||^2$로 표현할 수 있다.
\[\therefore J_{lr}(\Theta) = \frac{1}{n} \sum_{i=1}^{n} \mathcal{L}_{nll}(g^{(i)}, y^{(i)}) + \frac{1}{2} \lambda ||\Theta||^2\]여기까지가 배경지식이었다. 이제 Gradient Descent를 적용해보자. 먼저 $\mathcal{L}_{nll}$의 $\Theta$에 대한 gradient를 구해보자.
사실 그냥 미분하면 되는 것이라 설명이 필요하진 않지만, 대략 아래의 과정으로 정리하자.
\[\begin{align*} \frac{\partial \mathcal{L}_{nll}(g^{(i)}, y^{(i)})}{\partial \Theta} &= \frac{\partial \mathcal{L}_{nll}(g^{(i)}, y^{(i)})}{\partial g^{(i)}} \cdot \frac{\partial g^{(i)}}{\partial \Theta} \\ &= \left( -\frac{y^{(i)}}{g^{(i)}} + \frac{1 - y^{(i)}}{1 - g^{(i)}} \right) \cdot g^{(i)} (1 - g^{(i)}) x^{(i)} \\ &= (g^{(i)} - y^{(i)}) x^{(i)} \end{align*}\]그리고 L2 norm의 미분은 자명하니 생략하면,
\[\begin{align*} \nabla_{\Theta} J_{lr}(\Theta) &= \frac{1}{n} \sum_{i=1}^{n} \nabla_{\Theta} \mathcal{L}_{nll}(g^{(i)}, y^{(i)}) + \lambda \Theta \\ &= \frac{1}{n} \sum_{i=1}^{n} (g^{(i)} - y^{(i)}) x^{(i)} + \lambda \Theta \end{align*}\]위 식이 유도되는 것이다.
pseudo code로 표현하면 아래와 같다:
\[\begin{aligned} &\textbf{Algorithm LR-Gradient-Descent}(\theta_{\text{init}}, \theta_{0\text{init}}, \eta, \epsilon) \\[0.4em] &\begin{array}{r@{\quad}l} 1 & \theta^{(0)} = \theta_{\text{init}} \\ 2 & \theta_0^{(0)} = \theta_{0\text{init}} \\ 3 & t = 0 \\ 4 & \textbf{while } \left| J_{lr}\!\left(\theta^{(t)}, \theta_0^{(t)}\right) - J_{lr}\!\left(\theta^{(t-1)}, \theta_0^{(t-1)}\right) \right| > \epsilon \textbf{ do} \\ 5 & \qquad t = t + 1 \\ 6 & \qquad \theta^{(t)} = \theta^{(t-1)} - \eta \left( \frac{1}{n} \sum_{i=1}^{n} \left( \sigma\!\left( \left(\theta^{(t-1)}\right)^T x^{(i)} + \theta_0^{(t-1)} \right) - y^{(i)} \right)x^{(i)} + \lambda \theta^{(t-1)} \right) \\ 7 & \qquad \theta_0^{(t)} = \theta_0^{(t-1)} - \eta \left( \frac{1}{n} \sum_{i=1}^{n} \left( \sigma\!\left( \left(\theta^{(t-1)}\right)^T x^{(i)} + \theta_0^{(t-1)} \right) - y^{(i)} \right) \right) \\ 8 & \textbf{return } \theta^{(t)}, \theta_0^{(t)} \end{array} \end{aligned}\]첫 Gradient Descent 알고리즘에 LR을 끼워넣은 형태이다.
Stochastic Gradient Descent
기존 Gradient Descent는 전체 training set에 대해서 gradient를 계산하기 때문에, 데이터가 많아질수록 계산량이 많아지는 문제가 있다. Stochastic Gradient Descent는 전체 데이터를 다 써서 gradient를 계산하는 대신 일부 batch만 써서 근사하는 방법이다.
\[\begin{aligned} &\textbf{Algorithm Stochastic-Gradient-Descent} (\Theta_{\text{init}}, \eta, f, \nabla_\Theta f_1, \cdots, \nabla_\Theta f_n, T) \\[0.4em] &\begin{array}{r@{\quad}l} 1 & \Theta^{(0)} = \Theta_{\text{init}} \\ 2 & \textbf{for } t = 1 \textbf{ to } T \textbf{ do} \\ 3 & \qquad \text{randomly select } i \in \{1,2,\cdots,n\} \\ 4 & \qquad \Theta^{(t)} = \Theta^{(t-1)} - \eta(t)\nabla_\Theta f_i\!\left(\Theta^{(t-1)}\right) \\ 5 & \textbf{return } \Theta^{(t)} \end{array} \end{aligned}\]원래 업데이트 식에서 $f$ 대신 $f_i$를 쓰고, $\eta$도 iteration마다 달라질 수 있도록 $\eta(t)$로 표현했다.
Theorem
만약 $f$가 Convex이고, $\eta(t)$가 아래의 조건을 만족하는 수열이면, SGD는 최적의 $\Theta$로 항상 수렴한다.
Why SGD can be better than GD?
- 만약 f가 non-covex이고 여러 local minima가 존재한다면, GD는 local minima에 빠질 수 있지만, SGD는 noise 때문에 local minima에서 벗어날 수 있다.
- GD는 과적합이 발생할 수 있지만, SGD는 noise 때문에 과적합이 덜 발생한다.
- GD는 전체 데이터를 사용하기 때문에 계산량이 많지만, SGD는 일부 batch만 사용하기 때문에 계산량이 적다.
Exercise: GD and SGD
Question
데이터는 아래 3개가 있다.
\[\begin{align*} (x^{(1)}, y^{(1)}) &= (1, 1) \\ (x^{(2)}, y^{(2)}) &= (2, 0) \\ (x^{(3)}, y^{(3)}) &= (-1, 1) \end{align*}\]모델은 아래와 같으며 LR 모델이라고 생각하자.
\[g^{(i)} = \sigma(\theta x^{(i)} + \theta_0)\]현재 parameter가 $\theta = 0, \theta_0 = 0$이라고 하자. 그리고 $\eta(t) = 1$이라고 하자. 이때 (a) GD의 업데이트 과정 (b) SGD의 업데이트 과정을 3회 구하시오. SGD의 경우, 매 iteration마다 $i$를 1, 2, 3 순서로 선택한다고 하자.
2D input인 경우도 동일하게 풀면 된다.
Answer
LR에서
\[g^{(i)} = \sigma(\theta x^{(i)} + \theta_0)\]이고, 하나의 sample에 대한 NLL loss의 gradient는
\[\frac{\partial \mathcal{L}_{nll}(g^{(i)}, y^{(i)})}{\partial \theta} = (g^{(i)} - y^{(i)}) x^{(i)}\] \[\frac{\partial \mathcal{L}_{nll}(g^{(i)}, y^{(i)})}{\partial \theta_0} = (g^{(i)} - y^{(i)})\]이다.
(a) GD의 업데이트 과정
업데이트는
\[\theta^{(t)} = \theta^{(t-1)} - \eta(t) \cdot \frac{1}{n} \sum_{i=1}^{n} (g^{(i)} - y^{(i)}) x^{(i)}\]로 진행된다.
현재 parameter는
\[\theta = 0, \qquad \theta_0 = 0\]이므로 모든 데이터에 대해
\[g^{(i)} = \sigma(\theta x^{(i)}+\theta_0)=\sigma(0)=0.5\]이다.
| $i$ | $x^{(i)}$ | $y^{(i)}$ | $g^{(i)}$ | $g^{(i)}-y^{(i)}$ | $(g^{(i)}-y^{(i)})x^{(i)}$ |
|---|---|---|---|---|---|
| 1 | $1$ | $1$ | $0.5$ | $-0.5$ | $-0.5$ |
| 2 | $2$ | $0$ | $0.5$ | $0.5$ | $1$ |
| 3 | $-1$ | $1$ | $0.5$ | $-0.5$ | $0.5$ |
따라서 $\theta$에 대한 평균 gradient는
\[\frac{1}{3}\sum_{i=1}^{3}(g^{(i)}-y^{(i)})x^{(i)} = \frac{-0.5+1+0.5}{3} = \frac{1}{3}\]이다.
따라서 $\theta$의 업데이트는
\[\begin{align*} \theta^{(1)} &= \theta^{(0)} - \eta \frac{1}{3} \sum_{i=1}^{3}(g^{(i)}-y^{(i)})x^{(i)} \\ &= 0 - 1 \cdot \frac{1}{3} \\ &= -\frac{1}{3} \end{align*}\]이다.
또한 $\theta_0$에 대한 평균 gradient는
\[\begin{align*} \frac{1}{3}\sum_{i=1}^{3}(g^{(i)}-y^{(i)}) &= \frac{-0.5+0.5-0.5}{3} \\ &= -\frac{1}{6} \end{align*}\]이다.
따라서 $\theta_0$의 업데이트는
\[\begin{align*} \theta_0^{(1)}&=\theta_0^{(0)}-\eta\frac{1}{3}\sum_{i=1}^{3}(g^{(i)}-y^{(i)}) \\ &=0-1\cdot\left(-\frac{1}{6}\right) \\ &=\frac{1}{6} \end{align*}\]이다.
따라서 1회 GD update 후 parameter는
\[\theta^{(1)}=-\frac{1}{3}, \qquad \theta_0^{(1)}=\frac{1}{6}\]이를 2회 더 반복하면 구할 수 있다. (다만 sigmoid 계산이 손으로는 못 풀기에 여기까지…)
(b) SGD의 업데이트 과정
동일하게 $g^{(i)}=0.5$를 얻었다고 하자.
| $i$ | $x^{(i)}$ | $y^{(i)}$ | $g^{(i)}$ | $g^{(i)}-y^{(i)}$ | $(g^{(i)}-y^{(i)})x^{(i)}$ |
|---|---|---|---|---|---|
| 1 | $1$ | $1$ | $0.5$ | $-0.5$ | $-0.5$ |
따라서 $i=1$일 때 $\theta$의 업데이트는
\[\begin{align*} \theta^{(1)}&=\theta^{(0)}-\eta\cdot(g^{(1)}-y^{(1)})x^{(1)} \\ &=0-1\cdot(-0.5) \\ &=0.5 \end{align*}\]그리고 $\theta_0$의 업데이트는
\[\begin{align*} \theta_0^{(1)}&=\theta_0^{(0)}-\eta\cdot(g^{(1)}-y^{(1)}) \\ &=0-1\cdot(-0.5) \\ &=0.5 \end{align*}\]이후로도 동일하게 진행한다. (마찬가지로 sigmoid 계산이 손으로는 못 풀기에 여기까지…)
Optimizer
Momentum
Idea: 매 iteration마다 gradient의 “momentum”을 고려해서 업데이트 한다.
\[\begin{align*} v^{(t+1)}&=\alpha v^{(t)} -\eta g_t\\ \Theta^{(t+1)}&=\Theta^{(t)}+v^{(t+1)} \end{align*}\]Adagrad
Idea: 매 iteration마다 parameter마다 다른 learning rate를 적용한다.
\[\begin{align*} h^{(t+1)} &= h^{(t)} + g_t \odot g_t \\ \Theta^{(t+1)} &= \Theta^{(t)} - \frac{\eta}{\sqrt{h^{(t+1)}}+\epsilon} \odot g_t \end{align*}\]Adam
Idea: Momentum과 Adagrad를 결합한 방법이다.
// Skip…
Study Question
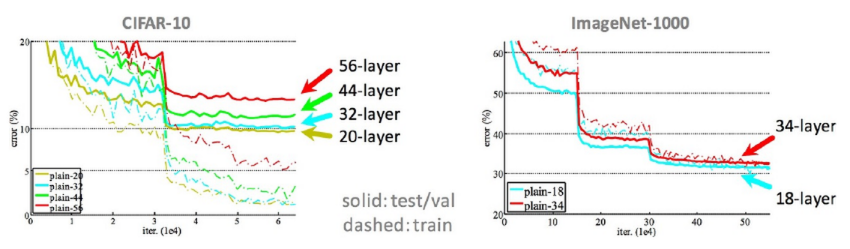
Q: 왜 계단이 있을까?
A: 보통 lr은 특정 iteration마다 감소시키는데, 계단이 있는 부분이 바로 lr이 감소된 부분이다. lr이 감소하면더 더 fine한 업데이트가 가능해지기 때문에, 점점 더 최적의 parameter에 가까워지는 것이다. 한편, layer가 많다고 해서 training error이 항상 감소하는 것이 아닌데, 우측 사진을 통해 확인할 수 있다. 이러한 문제는 degradation problem 이라고 한다.
Back-Propagation
이제 Neural Network에서 Gradient Descent를 어떻게 적용하는지 논의가 이어진다.
NN은 여러 layer로 수정되어 있고 아래처럼 여러 모듈들이 쌓인 것으로 볼 수 있다.
\[J = M_k ( M_{k-1} ( \cdots M_1(\Theta) \cdots ) )\]여기서 모듈(또는 레이어)는 liner layer, activation function, loss function 등이 될 수 있다. 일부는 parameter를 가지고 있고, 일부는 parameter가 없다. NN에서는 이중 parameter를 가지는 레이어를 올바르게 업데이트하는 것이 목표이다.
이를 이루기 위해서 일부 값들을 저장해두고 chain rule을 이용해서 각 layer의 gradient를 계산할 것이다.
Forward Pass
먼저 input이 들어오고 각 레이어를 순차적으로 지나는 것을 상상하자. 계산을 해가면서 중간 변수들을 미리 저장할 수 있다.
\[\begin{align*} u^{[0]} &= x \\ u^{[i]} &= M_i(u^{[i-1]}) \\ u^{[k]} &= J \end{align*}\]위처럼 말이다. 이들을 잘 활용하면 계산량을 크게 줄일 수 있다.
Backward Pass
이미 chain rule에 대해서는 알고 있다고 가정한다. 그리고 논의를 시작하기 위해 layer가 2개인 NN을 생각해보자.
\[z \xrightarrow{f} u \xrightarrow{g} J\]각 레이어는 $\frac{\partial J}{\partial \theta_{\text{Layer}}}$이 있어야 gradient descent를 할 수 있다. 예를 들어 $f$ 레이어의 업데이트는 $\theta_f = \theta_f- \eta \frac{\partial J}{\partial \theta_f}$로 표현할 수 있다. $g$ 레이어의 업데이트는 $\theta_g = \theta_g - \eta \frac{\partial J}{\partial \theta_g}$로 표현이 되겠다.
Back-Propagation은 뒷 레이어로부터 $\frac{\partial J}{\partial \text{Layer Output}}$을 받아 계산하는 과정이다. 왜 $\frac{\partial J}{\partial \text{Layer Output}}$가 모든 걸 해결해 주는지는 천천히 보자.
단, 여기서 주의할 점이 있다. layer의 입력과 출력이 스칼라라면 chain rule을 단순 곱으로 쓸 수 있지만, NN에서는 보통 입력과 출력이 벡터이다. 이 경우에는 미분값이 야코비안이 되므로, 뒤에서 받은 gradient와 야코비안을 곱하는 형태로 이해해야 한다.
먼저 g의 레이어의 관점에서 계산을 시작할 것이다. $\frac{\partial J}{\partial \text{Layer Output}}$ 는 곧 $\frac{\partial J}{\partial J} = 1$이다. 즉, 우리의 Back-Propagation은 1에서 시작한다.
$g$ 레이어는 입력으로 $u$를 받고, 출력으로 $J$를 낸다.
\[u \xrightarrow{g} J\]따라서 $g$ 레이어 입장에서 필요한 것은 두 가지이다.
첫 번째는 $g$ 레이어 자신의 parameter를 업데이트하기 위한 gradient이다.
\[\frac{\partial J}{\partial \theta_g}\]두 번째는 앞 레이어인 $f$에게 넘겨줄 gradient이다.
\[\frac{\partial J}{\partial u}\]Back-Propagation은 이 두 값을 계산하는 과정이라고 볼 수 있다.
먼저 $g$ 레이어의 parameter gradient를 보자. $g$의 출력은 $J$이므로 chain rule에 의해
\[\frac{\partial J}{\partial \theta_g} = \frac{\partial J}{\partial J} \frac{\partial J}{\partial \theta_g}\]이다. 여기서 첫 번째 항은 뒤에서 넘어온 gradient이다.
\[\frac{\partial J}{\partial J} = 1\]따라서
\[\frac{\partial J}{\partial \theta_g} = 1 \cdot \frac{\partial J}{\partial \theta_g}\]가 된다. 아직은 좌변과 우변이 같아서 좀 이상하게 보일 수 있지만, $f$ 레이어를 다룰 때 더 명확해질 것이다.
만약 $\theta_g$가 벡터라면 위 식은 더 정확히는 아래처럼 표현된다.
\[\nabla_{\theta_g} J = \left(\frac{\partial g}{\partial \theta_g}\right)^T \frac{\partial J}{\partial J}\]이제 $g$ 레이어가 앞 레이어로 넘겨줄 값을 보자. 앞서 규칙을 정한 것처럼 $g$는 뒷 레이어 $f$에게 $\frac{\partial J}{\partial u}$를 넘겨준다.
Chain rule에 의해, 스칼라인 경우에는
\[\frac{\partial J}{\partial u} = \frac{\partial J}{\partial J} \frac{\partial g}{\partial u}\]정리하면, $g$ 레이어는 앞에게 $\frac{\partial J}{\partial u}$를 넘겨주고, 자기 자신의 parameter gradient $\frac{\partial J}{\partial \theta_g}$도 계산할 수 있다.
다음으로 f 레이어를 보자. $f$ 레이어는 입력으로 $z$를 받고, 출력으로 $u$를 낸다.
\[z \xrightarrow{f} u\]따라서 $f$ 레이어 입장에서 필요한 것은 두 가지이다.
첫 번째는 $f$ 레이어 자신의 parameter를 업데이트하기 위한 gradient이다.
\[\frac{\partial J}{\partial \theta_f}\]두 번째는 앞 레이어인 input에게 넘겨줄 gradient이다.
(이 경우에는 마지막 layer이므로, 넘겨줄 레이어가 없지만, 일반적인 경우를 생각하기 위해서 표현해보자.)
$f$와 마찬가지로 chain rule에 의해
스칼라인 경우에는
\[\frac{\partial J}{\partial \theta_f} = \frac{\partial J}{\partial u} \frac{\partial u}{\partial \theta_f}\]이다. 이미 뒷 layer인 $g$로부터 $\frac{\partial J}{\partial u}$를 전달 받았기에 다시 계산할 필요 없이 바로 사용할 수 있다.
다변수인 경우에는 아래처럼 쓴다.
\[\nabla_{\theta_f} J = \left(\frac{\partial f}{\partial \theta_f}\right)^T \nabla_u J\]그리고 $f$ 레이어가 앞 레이어로 넘겨줄 값은
스칼라인 경우에는
\[\frac{\partial J}{\partial z} = \frac{\partial J}{\partial u} \frac{\partial u}{\partial z}\]이고, 다변수인 경우에는
\[\nabla_z J = \left(\frac{\partial f}{\partial z}\right)^T \nabla_u J\]이다.
이처럼 반복해서 각 레이어가 뒷 레이어로부터 $\frac{\partial J}{\partial \text{Layer Output}}$를 받아서 자기 자신의 parameter gradient와 앞 레이어로 넘겨줄 gradient를 계산하는 과정을 Back-Propagation이라고 한다.
Examples
아래에서 $v = \frac{\partial J}{\partial u}$, 즉 upstream gradient라고 표현하겠다.
Linear Layer
| forward pass | backward pass |
|---|---|
| $u = W z+b$ | $\nabla_z J = W^T v$ , $\nabla_W J = v z^T$ , $\nabla_b J = v$ |
ReLU Layer
| forward pass | backward pass |
|---|---|
| $u = \max(0, z)$ | $\nabla_z J = v \odot \mathbf{1}_{z > 0}$ |
Loss Function
이때 $v=1$ 인 경우가 대부분이다.
| type | forward pass | backward pass |
|---|---|---|
| Squared Loss | $\ell = \frac{1}{2} |u-y|^2$ | $\nabla_u J = (u-y)v$ |
| Logistic Loss | $\ell = y\log(1+\exp(-u)) + (1-y)\log(1+\exp(u))$ | $\nabla_u J = (\sigma(u) - y)v$ |
MLP example
\[\begin{align*} a^{[0]} &= x \\ z^{[k]} &= W^{[k]} a^{[k-1]} + b^{[k]} \\ a^{[k]} &= \sigma(z^{[k]}) \\ J &= y\log(1+\exp(-z^{[r]})) + (1-y)\log(1+\exp(z^{[r]})) \end{align*}\]위 가정에서 back propagation의 결과는
\[\begin{align*} \nabla_{z^{[r]}} J &= \sigma(z^{[r]}) - y \\ \nabla_{W^{[k]}} J &= \nabla_{z^{[k]}} J (a^{[k-1]})^T \\ \nabla_{b^{[k]}} J &= \nabla_{z^{[k]}} J \\ \nabla_{z^{[k-1]}} J &= \left((W^{[k]})^T \nabla_{z^{[k]}} J \right)\odot \sigma'(z^{[k-1]}) \end{align*}\]이 될 것이다.